

My OpenRouter bill hit $650 in 30 days. Not because I was running a startup with 10,000 users. Because I was running seven AI agents on my own infrastructure, using the wrong model for almost every job.
Quick Verdict: Routing 90% of high-volume, low-complexity AI tasks from Claude Opus 4.5 ($5/M input, $25/M output) to MiniMax-M2.7 ($0.30/M input, $1.20/M output) cut daily API burn from roughly $20 to under $2, with zero measurable quality loss. If you run any kind of multi-agent setup, model-to-task mismatch is probably your biggest hidden cost right now.
What Is This Architecture, Exactly?
I run what I call the Jarvis Ecosystem: seven named AI agents doing different jobs 24/7, backed by 15+ automated workflows. Shuri does research and trend spotting. Hulk monitors 20+ X accounts and handles engagement. Vision runs SEO audits. Wanda drafts content. Ant Man handles long-form articles. Each one is a distinct agent with its own system prompt, memory context, and task loop.
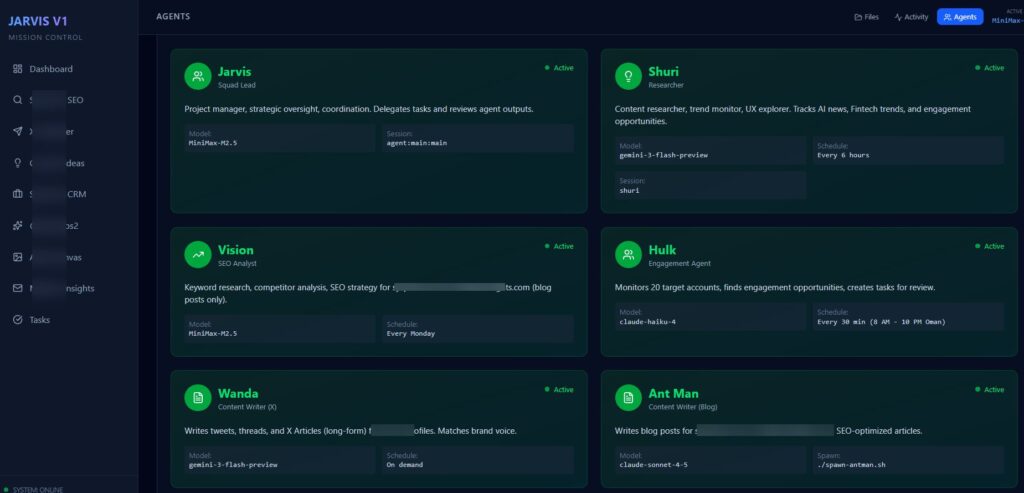
For months, every single one of them ran on Claude Opus 4.5. Because Opus is excellent, and that part is true. It’s a genuinely strong reasoning and coding model, priced at $5 per million input tokens and $25 per million output tokens on OpenRouter. But “excellent” isn’t always what you need. When you’re running 15,000+ API calls a month, the difference between “excellent” and “good enough” becomes a very specific dollar amount.
The Failure Mode: One Model for Everything
This is the pattern I see in most agentic setups that blow their budgets. Not wasteful prompting. Not unnecessary calls. Just one model assigned to every task, regardless of what the task actually requires.
Hulk’s job: Look at a post on X. Suggest a reply. That’s it. The task requires tone-matching and a bit of social context. It does not require the same model you’d use to debug a distributed system or write a complex financial analysis.
Vision’s job: Parse HTML. Check if a meta description is missing. Flag it. This is a grep operation with a language wrapper around it. Opus-level reasoning doesn’t move the needle here.
The “Inspector” workflow: A monitoring agent that checked whether other workflows ran successfully. I was spending real money to run what is essentially a status check.
I was building a model-to-task mismatch into every layer of the system, and the bill reflected it perfectly.
| Agent | Task Complexity | Model Used (Before) | Right Tier |
|---|---|---|---|
| Hulk (Engagement) | Low: tone matching, short replies | Claude Opus 4.5 | Bulk/cheap |
| Vision (SEO) | Low: metadata parsing, flag checks | Claude Opus 4.5 | Bulk/cheap |
| Shuri (Research) | Medium: summaries, trend spotting | Claude Opus 4.5 | Bulk/cheap |
| Wanda (Content Drafts) | Medium: structured drafts | Claude Opus 4.5 | Bulk/cheap |
| Jarvis (Orchestration) | High: planning, strategy | Claude Opus 4.5 | Keep on Opus |
| Ant Man (Long-form) | High: complex writing | Claude Opus 4.5 | Keep on Opus |
Six of seven agents were on a $25/M output model for tasks that don’t need it. That’s the whole story.
Why I Ignored the Signals
The OpenRouter dashboard showed me everything. Shuri and Hulk were burning 60% of the budget. The “Refill Successful” emails were hitting every few days.
I kept reading them and kept building. That’s the real failure, not the architecture, but the decision to treat “I’ll optimize it later” as an acceptable engineering stance on a live system. It’s not. Every day you defer that audit is a day you’re subsidizing a bad model-to-task match out of your own runway.
The other red flag I missed: my agents use a recursive memory system. Every turn was carrying 80 to 100K tokens of memory context into the prompt, for a task that was going to produce a 40-word response. Opus’s price per token is competitive when your outputs are substantial. When you’re sending a 100K token context to get back “Great thread, mind if I add a counterpoint?” you’re lighting money on fire.
The Switch: MiniMax-M2.7
MiniMax-M2.7 is a frontier-class model out of the Chinese LLM ecosystem, available on OpenRouter at $0.30 per million input tokens and $1.20 per million output tokens. Compare that to Claude Opus 4.5 at $5/M input and $25/M output, and you’re looking at a 17x gap on output pricing alone.
It’s not a budget model with budget output. MiniMax-M2.7 scores 80.2% on SWE-Bench Verified and 76.3% on BrowseComp, with a 197K context window and support from 16 infrastructure providers on OpenRouter. For conversational, social, and summarization tasks, the bulk of what most agents actually do, the output quality is genuinely comparable to Opus.
I ran a 48-hour test. Moved Hulk, Shuri, Vision, Wanda, and all workflow monitoring to MiniMax-M2.7. Kept Jarvis orchestration, Ant Man, and anything involving complex code debugging or strategic planning on Opus. Then I added a simple escalation rule: if a task fails twice, escalate to the Expert Tier. Otherwise, default to Efficiency Tier.
The Numbers
- Before: $15 to $22 per day
- After: $1.10 to $2.40 per day
- Monthly savings: roughly $550+
- Quality change: None detectable after final human review pass
For engagement and social banter tasks specifically, MiniMax-M2.7 actually performs better in practice. Claude Opus has a tendency to be overly structured and polite, which is fine for technical writing but not ideal for a punchy X reply. MiniMax is more direct, and that fits the platform better.
The entire “payroll” for seven AI agents now runs for less than a mid-tier SaaS subscription.
What Builders Should Actually Do
Audit your logs this week. Pull the top five highest-volume tasks by token count. For each one, ask: does this task require multi-step reasoning, or does it require pattern matching and coherent output? Most high-volume tasks are the second thing.
Build a model router, not a model default. Assign tiers: Bulk, Standard, Expert. Map tasks to them explicitly. Don’t let your architecture inherit a model choice you made during initial setup when speed was the priority and cost wasn’t on your radar yet.
Watch the Chinese LLM pricing curve. MiniMax-M2.7 is not the only option in this tier. DeepSeek V3.2, Qwen models, and others are all competing for the same “frontier performance at commodity pricing” slot. The gap between a $20/day setup and a $1.50/day setup is not a quality gap anymore. It’s just whether you’ve done the routing work.
FAQ
Is MiniMax-M2.7 actually reliable enough for production?
For high-volume, low-complexity tasks, yes. It has 16 providers on OpenRouter, which helps with uptime. For tasks where failure is costly, keep your escalation logic in place and let the model earn trust incrementally.
What tasks should stay on Opus-class models?
Anything requiring multi-step reasoning, complex code debugging, long-form strategic analysis, or tasks where a single wrong output has real downstream consequences. The rule of thumb: if a junior team member could do the task in 10 minutes, a bulk-tier model can probably handle it.
How do I build a model router without rebuilding my whole stack?
Add a task_tier parameter to your agent config. Default it to “bulk.” Add an escalation condition, task failure count over 1 or an explicit user flag, that swaps in the expert model. It’s a one-session change in most frameworks.
Will cheaper models stay this competitive, or will the gap close again?
The direction is clear: commoditization of baseline reasoning is accelerating. The models in this tier will keep improving faster than the pricing gap will close. Frontier model pricing will come down too, but the performance-per-dollar ratio on mid-tier models is a structural trend, not a temporary discount.