

You’ve been crafting the perfect AI prompt for 20 minutes. You’re tinkering with phrasing, adding examples, tweaking tone—and you’re still getting mediocre outputs. Here’s the kicker: you might be solving the wrong problem. While you’re polishing the front door (prompt engineering), the whole house behind it (context engineering) is falling apart.
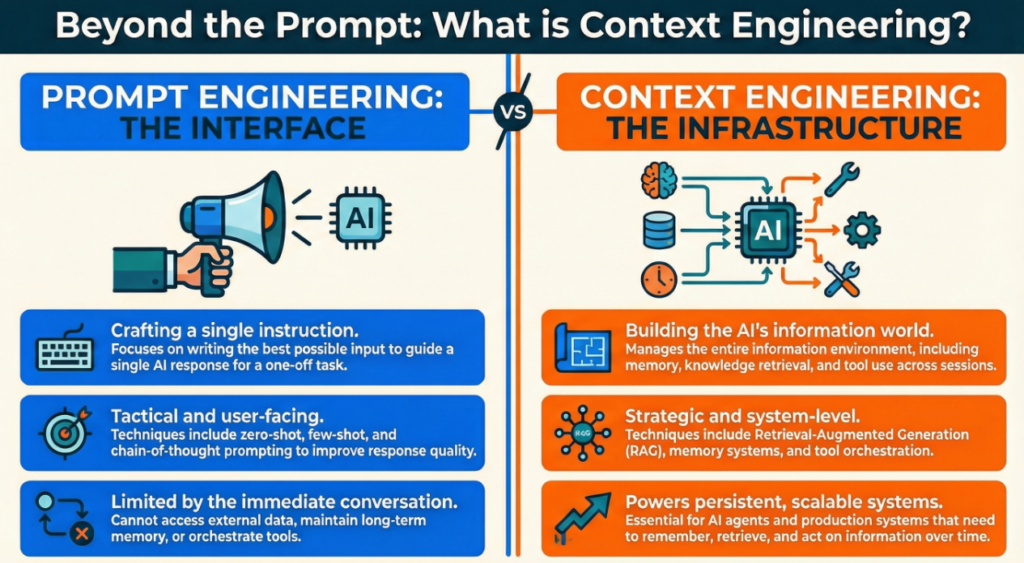
Context engineering builds the entire information environment for AI systems, managing memory, retrieval, and orchestration across sessions, while prompt engineering focuses on crafting individual inputs to guide a single AI response. Context engineering is infrastructure; prompt engineering is interface.
What Context Engineering Actually Is
Context engineering isn’t just a fancy rebrand of prompt engineering—it’s a completely different discipline. Think of it this way: if prompt engineering is writing a good email, context engineering is building the entire email system, inbox filters, search functionality, and message history that makes that email useful.
Context engineering manages the entire information payload delivered to large language models during inference. It’s about systematically optimizing what the AI sees, remembers, and accesses—not just what you type in the chat box. This includes retrieval-augmented generation (RAG), memory systems, tool orchestration, and multi-agent frameworks.
The discipline emerged because models kept hitting walls. You’d feed GPT-4 a question, it would hallucinate, or forget critical details from earlier in the conversation. Context engineering fixes that by designing systems that continuously feed the AI the right information at the right time.
Why This Shift Matters Now
Model context windows have exploded. We’ve gone from GPT-3’s 2,048 tokens to models like Magic LTM-2 handling 100 million tokens (think 10 million lines of code or 750 novels). But bigger windows don’t automatically mean better outputs—they mean you need better systems to manage what fills those windows.
Context engineering has become essential for AI agents and production systems because these applications need sustained, meaningful interactions—not just one-off Q&A. An agent handling customer support needs to remember your previous tickets, pull from your account history, and adapt as the conversation evolves. That’s context engineering territory.
What Prompt Engineering Still Does Best
Prompt engineering is the art of crafting inputs—questions, instructions, examples—that coax better responses from AI. It’s user-facing and tactical. You’re writing the prompt itself: “Summarize this in bullet points,” “Act as a Python expert,” or “Think step-by-step before answering”.
Solid techniques include zero-shot prompting (direct instructions with no examples), few-shot prompting (showing 2-3 examples first), and chain-of-thought prompting (asking the model to reason aloud before concluding). These work great for one-time tasks where you don’t need the AI to remember anything or fetch external data.
But here’s where it breaks down: prompt engineering assumes the model already has everything it needs in its training data or in your single message. If the answer requires current stock prices, your company’s internal docs, or details from a conversation three days ago, prompt engineering alone won’t cut it.
The Limits Are Real
I’ve watched teams spend weeks perfecting prompt templates, only to hit a wall when the AI hallucinates outdated information or can’t reference external knowledge bases. Prompt engineering can’t solve data freshness, can’t manage long-term memory, and can’t orchestrate multiple tools. That’s not a failure of the technique—it’s just not what it was built for.
The Head-to-Head Breakdown
| Aspect | Prompt Engineering | Context Engineering |
|---|---|---|
| Focus | Crafting individual inputs and instructions | Building entire information infrastructure |
| Scope | Single interaction, one-off tasks | Multi-session, persistent systems |
| Who Uses It | End users, content creators | Developers, system architects |
| Techniques | Zero-shot, few-shot, chain-of-thought | RAG, memory systems, tool orchestration |
| Goal | Guide AI response quality and format | Manage AI’s knowledge, state, and scalability |
| Limitations | Can’t access external data or maintain memory | Requires infrastructure and engineering effort |
Context Engineering in Action
RAG (retrieval-augmented generation) is the poster child of context engineering. Instead of hoping the model knows your company’s policies, RAG fetches relevant documents from a knowledge base in real-time, injects them into the context, and then generates a response. This decouples factual content from the model’s behavior logic, so you can scale knowledge without retraining.
AI agents take this further by making context dynamic. An agent might start a conversation, realize it needs current stock data, call a financial API, use that fresh info to continue, then store the interaction in memory for future reference. This isn’t something you can do with clever prompting—it requires orchestration, state management, and tool integration.

Memory systems are another piece. They persist user interactions, preferences, and feedback across sessions. Think of a customer support bot that remembers you called last week about billing—it doesn’t re-ask the same questions. That’s context engineering handling long-term state.
The ACE Framework Example
Recent research on “Adaptive Context Engineering” (ACE) showed that comprehensive, evolving contexts enable self-improving LLM systems with low overhead. ACE matched top-ranked production agents on benchmarks despite using smaller open-source models, proving that smart context management can outperform brute-force prompt tuning.
When to Use What
Use prompt engineering when you need quick wins on defined tasks: summarizing a doc, generating a product description, or answering a straightforward question. It’s fast, requires minimal setup, and works beautifully for one-off interactions where the model already has enough context.
Use context engineering when you’re building production systems, AI agents, or anything requiring external data, memory, or tool access. If your AI needs to reference a database, remember past conversations, or scale across thousands of users, you’re in context engineering territory.
Honestly, most serious AI applications need both. You still need well-crafted prompts (prompt engineering) to instruct the model on how to use the information, but you need context engineering to ensure the right information is even available.
What’s Coming Next
The research gap is glaring: models are great at understanding complex contexts but terrible at generating equally sophisticated long-form outputs. We’ve nailed input, but output lags behind. Expect the next wave of context engineering to focus on output orchestration—helping models produce coherent, multi-step, long-form responses that match their comprehension abilities.
Models with native million-token context windows (like MiniMax-M1-80k with 1M tokens or Qwen3 extending to 1M with reasoning) are already here. But bigger windows create new challenges: context distraction (the AI gets overwhelmed), context poisoning (bad data corrupts responses), and context clashes (conflicting information confuses the model). Context engineering techniques like summarization, filtering, and dynamic retrieval are how we’ll manage that.
Multi-agent systems are the frontier. Instead of one AI juggling everything, you orchestrate multiple specialized agents—each with its own context and toolset—coordinating to solve complex problems. This requires next-level context engineering: managing agent state, memory handoffs, and tool chains across distributed systems.
The Verdict
Look, if you’re just drafting emails or generating blog ideas, keep prompt engineering. It’s lightweight and effective. But if you’re building anything that needs to remember, retrieve, or orchestrate—customer support bots, research assistants, code agents—you’re doing context engineering whether you call it that or not.
Stop treating every AI problem like a prompt problem. Sometimes the issue isn’t how you’re asking—it’s what the AI has access to in the first place. Context engineering gives you the infrastructure to build AI that doesn’t just respond well once, but performs consistently across thousands of interactions.
The future isn’t better prompts. It’s better systems.
FAQ
What’s the main difference between context engineering and prompt engineering?
Prompt engineering crafts the input instructions for a single AI interaction, while context engineering builds the entire information system—retrieval, memory, orchestration—that supports sustained AI operations across multiple sessions.
Can I use prompt engineering without context engineering?
Yes, for simple, one-off tasks where the model already has enough information in its training data or your message. But for production applications requiring external data, memory, or tool access, you’ll need context engineering infrastructure.
What are the best models for context engineering right now?
Magic LTM-2-Mini leads with a 100 million token context window, ideal for massive codebases. For reasoning over extended contexts, Qwen3-30B-A3B-Thinking-2507 offers 256K extendable to 1M with thinking mode. For balanced production use, Gemini 2.5 Pro and Claude 4 Opus provide robust 200K+ windows with strong toolchain support.
Is context engineering replacing prompt engineering?
No. They serve different purposes. Prompt engineering remains essential for instructing how the model should use information, while context engineering ensures the right information is available. Most serious AI applications need both working together.